Unlocking the Full Power of Data Structures and Algorithms: A Modern Guide

Niklaus Wirth was a Swiss computer scientist and, in the year 1976, he wrote a book entitled Algorithms + Data Structures = Programs. This formula still holds even in 2023 and still will for a long time.
Almost all problems require a deep knowledge of Data Structures, and many times these hide under unassuming wording.
As such, understanding Data Structures and algorithms is essential in our everyday coding adventures and projects.
First, we will take a look at the fundamentals of the algorithms and then advance slowly until we get to the more advanced topics.
What is an Algorithm?
When you want to do an action, you have a set of steps that you follow and, an algorithm simply put is the sequence of steps that you need to do to reach your goal.
For example, changing a lamp. To do that you need to get a lamp, remove the old one, and then put in the new one.
In this example, the algorithm is all of those steps, in order.
What is a Data Structure and why do we need them?
A Data structure is a way to structure the data in a way that makes the next operations more efficient.
There are a lot of Data Structures that optimize certain operations, but there is no Structure that is good for every case.
Common Data Structures used
There are, in general terms, 7 Data Structures that are the most usual.
Inside every of the following, further optimizations are possible and, as such, there are more categories inside each one.
-
Arrays
-
Stacks
-
Queues
-
Linked Lists
-
Trees
-
Graphs
-
Hash Tables
We will start looking at each one and see the highlights of each one and what optimizations it implements.
Arrays
An Array is arguably the simplest Data Structure. You can think of it as a list of things without order.
There are 2 main implementations: dynamic arrays and static arrays.
In the dynamic version, found in Python, for example, the list has no predefined size.
This has some performance implications, since if the size changes, the whole array needs to be reallocated, which can cause a performance hit.
In the static array, the size is predefined and cannot be changed after the fact.
These are, generally found in higher-performance languages like C.
Stacks
Stacks are used, for example, in the undo option of your favorite editor for example. This is implemented by saving the previous states in a list and removing the last inserted one every time there is the need to undo it.
This is the basic functioning of a LIFO (Last In First Out).
Normal operations of a Stack include peek, pop, insert, and a method to check if is empty. Peek retrieves the topmost element without actually removing it, pop is the same, but it removes the element and the insert places an item on the stack.
Queues
Queues are reminiscent of real-life queues, meaning that, similarly to a Stack it stores the elements linearly, however, it implements the FIFO method.
FIFO means First In First Out which in a Queue means that the first element inserted is the first element being popped.
The basic operations of a queue are:
-
Top
-
Enqueue
-
Dequeue
-
IsEmpty
Top corresponds to the peek of a Stack, enqueue puts an element onto the queue, dequeue removes an element, and IsEmpty as the name implies, checks if the queue is empty.
Linked Lists
A Linked List like a dynamic array does not have its size predefined, meaning that it can grow or shrink dynamically, however, unlike a dynamic array, it is not a contiguous block of memory, instead, each element is in a different portion of the RAM.
Metadata associated
A Linked List works by having metadata associated with each element. There are 2 variations of Linked Lists, Singly-Linked Lists, and Doubly-Linked Lists.
In a Singly-Linked List, the metadata includes a pointer to the next element. In a Doubly-Linked List, there is also a pointer to the previous element so that movement can be bidirectional.
The metadata also can contain other useful pointers for example the address of the head.
How to navigate a Linked List
Navigating a linked list is done by moving one element at a time, meaning that random reads are not possible.
Adding elements can also be costly because you either have to update the metadata to include the new tail or navigate to the end and add the next element there.
Similarly, if the Linked List metadata includes the head, inserting or deleting an element in the head can also be costly, since every element needs to be updated.
Common operations
-
InsertTail
-
InsertHead
-
Delete
-
DeleteHead
-
DeleteTail
-
Search
-
IsEmpty
As common operations go, it needs to be possible to insert and remove elements at every point and search and detect if they are empty.
Trees
In Computer Science, a tree is a Data Structure that has a particular shape, similar to the one below.
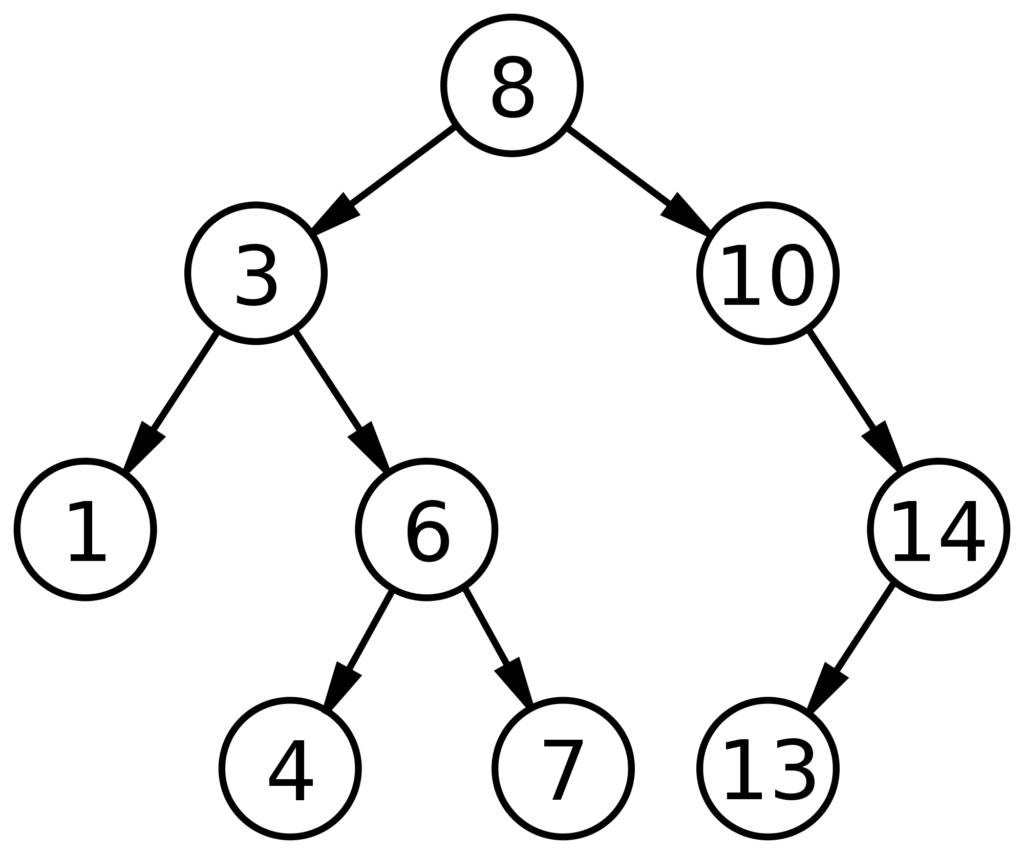
Binary Tree
Is usual to represent the nodes as circles with their value inside. In the example, the number 8 is the so-called root of the tree, and the leaves are the nodes without a child.
Other terminology is neighbors (the direct child and parent of a given node), the depth (number of parents until the root which has degree 0), the degree (number of children of a given node), and the breath (the number of leaves in the entire tree).
Another essential characteristic is whether the tree is balanced or not.
For a tree to be balanced, the number of leaves on the left of the root has to be the same as on the right.
Overall this is a very important Data Structure and there are many variations of this, accordingly to its characteristics.
We will now take a look at 2 notable types of trees, the Binary Tree and Trie.
Binary Tree
A Binary Tree is a tree that enforces the limit of 2 children per node and can be (or not) ordered.
This type of tree is especially useful when searching for numbers since when ordered, it allows cutting the searching space by half (when balanced).
To traverse such a tree there are 2 methods, Breath First and Depth First.
In a Breath First approach, we traverse from left to right and top to bottom, meaning that we visit all nodes, starting at the root, and visiting first the left node and then the right one.
By comparison, in Depth First we instead traverse all nodes, from root to leaf, looking at the farthest left node that was not visited yet.
Trie
A Trie is a data structure, similar to a tree, that aims strings (lists of characters) and other structures with the same prefix. For this reason, they are called prefix trees.
It works by segmenting the data into chunks and grouping the prefixes that are the same. Something like in the image below.

Here we have 3 words represented in a trie: Apple, Ant, and Appetite. We start with the root element aptly named ROOT then we write the words, trying to match as much of the prefix as we can.
I also colored the leaves a different color to be easier to identify and distinguish from the other nodes.
Common uses include dictionaries, Search Engines, and even IP routing.
Graphs
Graphs are, in their essence, a fundamental Data Structure used in computer science and are widely used to represent and manipulate data.
A graph is a mathematical structure that consists of a set of vertices (or nodes) and edges that connect them.
These edges represent relationships or relations between 2 nodes.
Graphs are used to model very interconnected data with complex relationships and allow visualization simply and intuitively.
One of the most important examples is the use of Databases such as Neo4j.
Hash Tables
Hash tables allow to the creation of an indexable structure (just like an array) but using any hashable element as the index.
By hashable I mean that is possible to generate a unique value from that element.
This data structure, ideally, allows for the insertion and retrieval of elements in constant time, while not allowing them to traverse linearly like is possible in an array.
This works by storing a collection of values associated with a key.
To retrieve elements, we simply do the hash of that index and we get the location of the value by looking at the key.
The only downside is the collisions that can occur, which happen when 2 values have the same hash.
This makes hash tables a fast and efficient way to store and retrieve data in computer science applications.
Finally, hash tables are ideal for use in a wide range of applications, such as database indexing, web caching, and data compression.
Conclusion
In conclusion, algorithms and data structures play a crucial role in computer science and are the building blocks of many modern software systems.
Understanding the basics of algorithms and data structures is essential for any software developer, as they provide a way to solve complex problems in a more efficient and organized manner.
From simple sorting algorithms to complex graph algorithms, there is a vast range of algorithms and data structures available, each with its own strengths and weaknesses.
As technology continues to evolve and new problems arise, algorithms and data structures will continue to play a vital role in solving these challenges and making our lives easier.